New Feature
First a brief description of a new feature upcoming in PseudoTV. I have 2 systems that run XBMC and PseudoTV in my house, one in my living room and one in my bedroom. There have been several times that I've wanted to stop watching something in the living room and continue it upstairs. That is now possible. There is a new option to specify the directory to store PseudoTV playlists and settings. If two systems share this directory, then they will both use the same set of channels and (with only minor differences) they will play them at the same times.
Implementation
This leads to the second part of this post: File locks over a network when using multiple platforms. What if I turn on TV 1 and it starts loading the channels. I then turn on TV 2 and it starts loading. If TV 1 modifies any of the playlists, TV 2 won't necessarily know and things will get screwed up. Who is allowed to extend the channel lists? Who is allowed to write to the settings? This is where file locks come into play.
Locking a file on a local hard drive so that other programs can't access it is generally possible, as long as you're writing for that platform specifically. It can even be done on networked drives, again, presuming that the systems are the same and you target them specifically. XBMC runs on multiple platforms so I can't presume anything of that sort. So how can I make sure that two instances don't start writing to the same file at the same time? How do I lock files?
The code is actually pretty simple...here are the steps:
1. Create a general lock file master list (I use FileLock.dat).
2. In order to lock a file, the first step is for a system to rename the master list to some random number filename (87385.lock). This is effectively the atomic operation needed for locking files.
3. In order to verify that it succeeded, it makes sure it can open the file for reading. If it can, then it now has control over the master file lock list.
4. Look in the list to see if the file you wish to lock is already there. If it is, then it's locked. If it isn't, then add it to the list.
5. Rename the list back to the original name.
That's it. The file is locked.
Issues
If only it where that simple. The problems arise when things don't work like they should. How does the system know that it needs to create the lock list, and not that it doesn't just need to wait for another system to rename it back? What happens if a system crashes and doesn't release a lock file, is that file permanently locked?
I'll start with the first question. If any given system can't get access the master list for some amount of time (10 seconds) then it needs to just create the list. Since, once a system has control over the list, the operations themselves take almost no time at all then the timeout value is very reasonable. Is this perfect? No. It will not scale very well. I would not recommend using this method for 10 machines at once since it may cause problems. For a small scale, though? Great.
What about the second issue, where a file can become permanently locked? This is resolved by adding a random value to the same line as the locked file in the list. For example:
918374, MyLockedFile.txt
Every few seconds, the owner of that file will re-lock the file with a new random number. Whoever wants access to MyLockedFile.txt will just watch the list and make sure that number actually changes. If it doesn't change for some amount of time (10 seconds) then it assumes that the lock is dead, and it rewrites it. If it does change then the lock is valid.
There's nothing terribly difficult about this method, but it took me a while to figure out...hopefully others will benefit from this. The python code where I use this is here.
Monday, August 8, 2011
Monday, July 11, 2011
Works in Progress
I've mentioned in the past that the next version of PseudoTV will have some additional features. I'm going to go through some of those, and then in the next week(s) you'll be able to try them on stable-pre.
Directory Channels
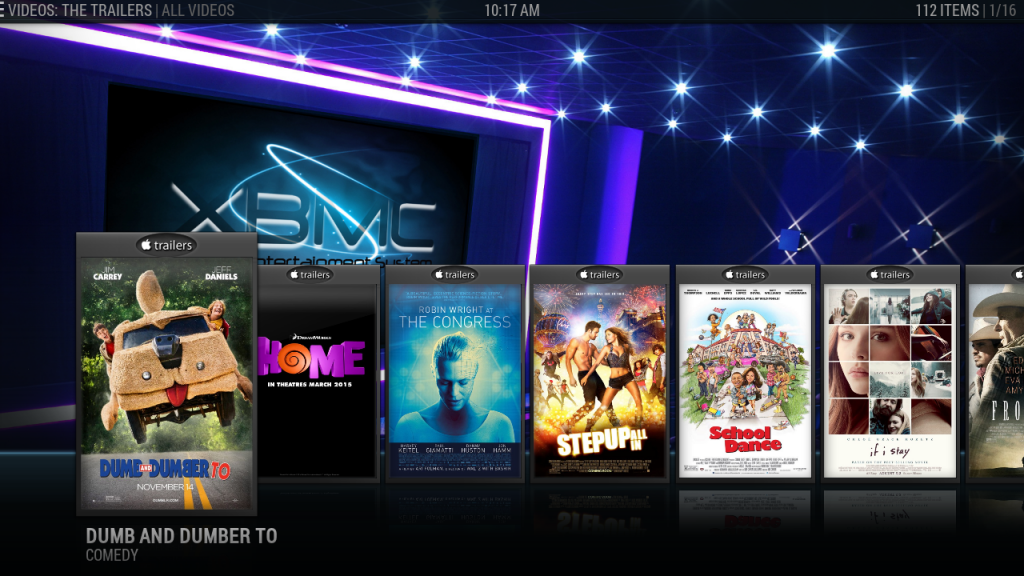
This feature has been requested several times in the past, but I hadn't really understood the reason for it. People wanted to create channels based on a certain directory of media that wasn't scraped into XBMC. Why? For myself, the motivation came when I discovered HD-Trailers.NET Downloader. My wife laughs at me for having this, but I really like having a channel that plays all of the newest trailers. So I setup this program to download the newest ones every night. Of course these won't scrape into XBMC so I need a way to play them...hence directory channels.

Background Channel Loading
One complaint that I've personally had about PseudoTV was that, at times, startup would take too long. I'd have to sit and wait for each channel to update. This isn't a problem if all of your media is connected to the computer running XBMC, but one of my machines is connected over dreaded WiFi. Channel updates could take up to 15 seconds each...I'm not patient enough to wait for 20-something channels to update. In comes background updating.
On startup, only channels that are ready to go will actually be loaded. You may end up with as little as 1 channel actually enabled when PseudoTV starts playing. After that, it will update and load the rest of the channels in the background, giving you a little message that pops up after each one is available. No more waiting! Combined with the previous version's ability to load up to 5 days of data in advance in the background, there should be virtually no updating of channels on startup and if updating is necessary it will be done without forcing delays. Ah, multithreading, I'm a fan.
Channel Rules
You may have noticed in the above screenshot the addition of a new button: Channel Rules. This will hopefully allow me to give users a lot more flexibility over how each channel is setup. It also doesn't force it on them, so you can safely ignore its presence if you want. Here's what the rule screen (currently) looks like:

It will have a bit of a different interface that I hope people find intuitive enough. It will contain only a list. Each channel will start with no rules. When you select an empty rule to modify, you get this:

From there you can select the rule type and then just fill in the rule options. The number of rules in a channel isn't limited, but it's possible to create a garbage channel if you're not careful. For example, if the channel type is TV show, the show is Firefly, and you make a rule that says not to play the TV show Firefly. That would be stupid. Don't do that.
I don't have a final list of rules yet, but I'm working on it. This is the big feature that will delay this release, so please don't throw things at me if it takes too long! I'll make sure to update the PseudoTV thread with any stable-pre updates.
Worth mentioning
The video parser will now determine the length of MOV files. Turns out that they are virtually the same format as MP4, I only needed to send them to that same parser and everything worked. Huh, who knew.
Directory Channels
This feature has been requested several times in the past, but I hadn't really understood the reason for it. People wanted to create channels based on a certain directory of media that wasn't scraped into XBMC. Why? For myself, the motivation came when I discovered HD-Trailers.NET Downloader. My wife laughs at me for having this, but I really like having a channel that plays all of the newest trailers. So I setup this program to download the newest ones every night. Of course these won't scrape into XBMC so I need a way to play them...hence directory channels.

Background Channel Loading
One complaint that I've personally had about PseudoTV was that, at times, startup would take too long. I'd have to sit and wait for each channel to update. This isn't a problem if all of your media is connected to the computer running XBMC, but one of my machines is connected over dreaded WiFi. Channel updates could take up to 15 seconds each...I'm not patient enough to wait for 20-something channels to update. In comes background updating.
On startup, only channels that are ready to go will actually be loaded. You may end up with as little as 1 channel actually enabled when PseudoTV starts playing. After that, it will update and load the rest of the channels in the background, giving you a little message that pops up after each one is available. No more waiting! Combined with the previous version's ability to load up to 5 days of data in advance in the background, there should be virtually no updating of channels on startup and if updating is necessary it will be done without forcing delays. Ah, multithreading, I'm a fan.
Channel Rules
You may have noticed in the above screenshot the addition of a new button: Channel Rules. This will hopefully allow me to give users a lot more flexibility over how each channel is setup. It also doesn't force it on them, so you can safely ignore its presence if you want. Here's what the rule screen (currently) looks like:

It will have a bit of a different interface that I hope people find intuitive enough. It will contain only a list. Each channel will start with no rules. When you select an empty rule to modify, you get this:

From there you can select the rule type and then just fill in the rule options. The number of rules in a channel isn't limited, but it's possible to create a garbage channel if you're not careful. For example, if the channel type is TV show, the show is Firefly, and you make a rule that says not to play the TV show Firefly. That would be stupid. Don't do that.
I don't have a final list of rules yet, but I'm working on it. This is the big feature that will delay this release, so please don't throw things at me if it takes too long! I'll make sure to update the PseudoTV thread with any stable-pre updates.
Worth mentioning
The video parser will now determine the length of MOV files. Turns out that they are virtually the same format as MP4, I only needed to send them to that same parser and everything worked. Huh, who knew.
Tuesday, June 28, 2011
Version 1.2.1
Version 1.2.1
A new version was officially released yesterday, version 1.2.1. Given that the "incremental" version number changed, you know that this is a small release. So true. Let's see what's in it, though.
First off, two new skins were added. Here is the Simplicity skin by Zepfan:

And here is the JX 720 skin by Steveb:

As far as bug fixes go, there are several that were handled in here. Only 1 of them is even worth mentioning, though, and it only because of its simplicity and the difficulty I had in finding it. For a certain user, the AVI parser was breaking on one of his files. We went back and forth several times, each time I added additional debugging code. I finally narrowed it down.
When reading a chunk of data, I had this code:
def read(self, thefile):
data = thefile.read(4)
A new version was officially released yesterday, version 1.2.1. Given that the "incremental" version number changed, you know that this is a small release. So true. Let's see what's in it, though.
First off, two new skins were added. Here is the Simplicity skin by Zepfan:

And here is the JX 720 skin by Steveb:
As far as bug fixes go, there are several that were handled in here. Only 1 of them is even worth mentioning, though, and it only because of its simplicity and the difficulty I had in finding it. For a certain user, the AVI parser was breaking on one of his files. We went back and forth several times, each time I added additional debugging code. I finally narrowed it down.
When reading a chunk of data, I had this code:
def read(self, thefile):
data = thefile.read(4)
try:
self.size = struct.unpack('i', data)[0]
except:
self.size = 0
# Putting an upper limit on the chunk size, in case the file is corrupt
if self.size < 10000:
self.chunk = thefile.read(self.size)
else:
self.chunk = ''
self.size = struct.unpack('i', data)[0]
except:
self.size = 0
# Putting an upper limit on the chunk size, in case the file is corrupt
if self.size < 10000:
self.chunk = thefile.read(self.size)
else:
self.chunk = ''
The point of this is that it will read in the data associated with the chunk. Not a big deal...read the size itself, and then read the data. I even limit the amount of data to read just in case the file is corrupt. I missed something important, though: the size value is signed. This means that in a file that is corrupt, I may read a negative number. In Python, performing a read with a negative size will read in the entire file, causing problems. So the fix was simple:
if self.size > 0 and self.size < 10000:
self.chunk = thefile.read(self.size)
else:
self.chunk = ''
self.chunk = thefile.read(self.size)
else:
self.chunk = ''
Not a big deal.
Next time I'll discuss some of the things going into 1.3.0.
Subscribe to:
Posts (Atom)